
Report: Solana Activity Hits Record High Despite SOL’s 33% Q1 Drop
Solana hits record transaction volume in Q1 2026 despite SOL's 33% price drop.
CryptoPotato1 min read

Qwen 3.7 Max debuted on May 14, 2026, ranking #13 globally in text and making Alibaba the sixth-ranked AI lab worldwide. The Plus variant will be open source, while the Max flagship will remain proprietary, reflecting Alibaba's strategy to monetize its top models.
Mentioned in this story
🚀🚀Qwen3.7 Preview lands on Arena !
Here come Qwen3.7-Max-Preview & Qwen3.7-Plus-Preview. Alibaba now #6 lab in Text, #5 in Vision.⚡️⚡️
Can't wait to release Qwen3.7 series models!Stay tuned! @arena
— Qwen (@Alibaba\_Qwen) May 18, 2026 This is the same playbook Alibaba ran with Qwen 3.6 Max in April. Validate first. Market later. It's a smarter move than it looks—Arena AI uses blind, crowd-sourced comparisons, so the rankings reflect what real users actually prefer, not what a benchmark press release says. The results held up. As *Decrypt* covered when Qwen 3.6 Max dropped, Alibaba has been quietly tightening the gap with Western frontier labs for months. Qwen 3.7 Max-Preview lands at #13 overall in Text Arena, ranking seventh in math, ninth in expert-level prompts, and ninth in software and IT. That makes Alibaba the sixth-ranked AI lab globally in text, and fifth in vision capabilities. The open-source question matters here. Alibaba killed the free tier of Qwen Code last month and has been moving its best models behind a paywall. Qwen 3.7 follows the same logic: Plus gets open-sourced, Max stays proprietary. The official confirms this directly. Developers who want the best Qwen will be paying for it. That said, the best small, open-source agentic coding models for local inference are based on Qwen, and this new family promises to improve on what made 3.6 so popular among AI enthusiasts. Both models (Plus and Max) are currently locked into deep thinking mode, with web search and code interpreter disabled. This is a preview. The full release was expected at the Cloud Summit on May 20. We ran a quick test on Qwen 3.7 Max to see how it stacks against another Chinese model, Xiaomi Mimo, which performed extremely well. Here is what we found.
Qwen 3.7 Max was released on May 14, 2026.
Qwen 3.7 Max ranks #13 globally in text and makes Alibaba the sixth-ranked AI lab worldwide.
No, Qwen 3.7 Max will not be open source; only the Plus variant will be available as open source.
Qwen 3.7 Max focuses on setting and efficiency in storytelling, while MiMo offers richer texture and layered narratives.
Solana hits record transaction volume in Q1 2026 despite SOL's 33% price drop.

You can now buy Bitcoin, XRP, and more directly in ChatGPT through MoonPay!

Coinbase's Katie Harries: We Welcome Wall Street Competition

SEC postpones plans for tokenized stock trading on crypto platforms amid concerns.

Bitcoin's price could fall to $72,500 before rebounding, according to analysis.

Vitalik Buterin states his influence over Ethereum Foundation is shrinking intentionally.
See every story in Crypto — including breaking news and analysis.
We ran Qwen 3.7 Max on the same prompt we used for MiMo-V2-Pro: a time travel story built around the protagonist's cultural background, a philosophical time paradox, and a specific historical setting. Both models understood the assignment. What they did with it could not be more different. Qwen went Caribbean. The story opens in 2150 Neo-Borinquen—a submerged Puerto Rico where titanium seawalls are being eaten alive by a synthetic bacteria called the Crimson Blight. The protagonist wears a digital cemí, a holographic projection of the ancient Taíno spirit stone his grandmother gave him. The cultural specificity is immediate and correct: the Ostionoid lineage, the reference to Yemayá, the Afro-Caribbean heritage. Qwen didn't Google translate "Latin American" into a setting, instead its framing makes it obvious, which is something many other models fail to understand. However, the writing is tighter and more angular than MiMo's. Compare the two openings. MiMo: "*The chronopod smelled of burnt copal when it opened. The air hit him first —thick, almost chewy with moisture, carrying the green rot of jungle and something sweeter underneath: wild cacao blooming in the understory."* Qwen: *"The neon-drenched smog of Neo-Borinquen in the year 2150 tasted of ozone and dying kelp. Jose Lanz stood on the precipice of the floating seawall, his amber eyes reflecting the sickly, pulsing magenta of the city's failing holographic advertisements."* MiMo goes deep into texture. Qwen goes wide into setting. Both work. They're just different instincts. Even as both models are decent in the opening, they go in completely different directions as the story moves forward. This was tested several times with the same result. Qwen goes straight to the grain—no elaboration, no richness. It follows the prompt, though, just not in an engaging way. The paradox resolution is the bigger difference. In Qwen’s story, the key element of the tale was super easy to understand. There was pollution in the futuristic society. Jose travels back in time to solve the issue, but the pollution was caused by the arrival of its time machine in the past, so he couldn’t solve the problem because it was *already* an unsolvable problem in his own timeline. The story is shorter than MiMo's and less maximalist. Where MiMo built five full chapters with layered interiority and a slow payoff, Qwen wrote a sharp, efficient short story that lands its punch and ends. Neither approach is wrong. If MiMo writes like a novelist, Qwen writes like a very good short story writer. Depending on the use case, one of those is exactly what you want. You can read our stories in our Github repo.
Same prompt as MiMo. Better result. Significantly better.
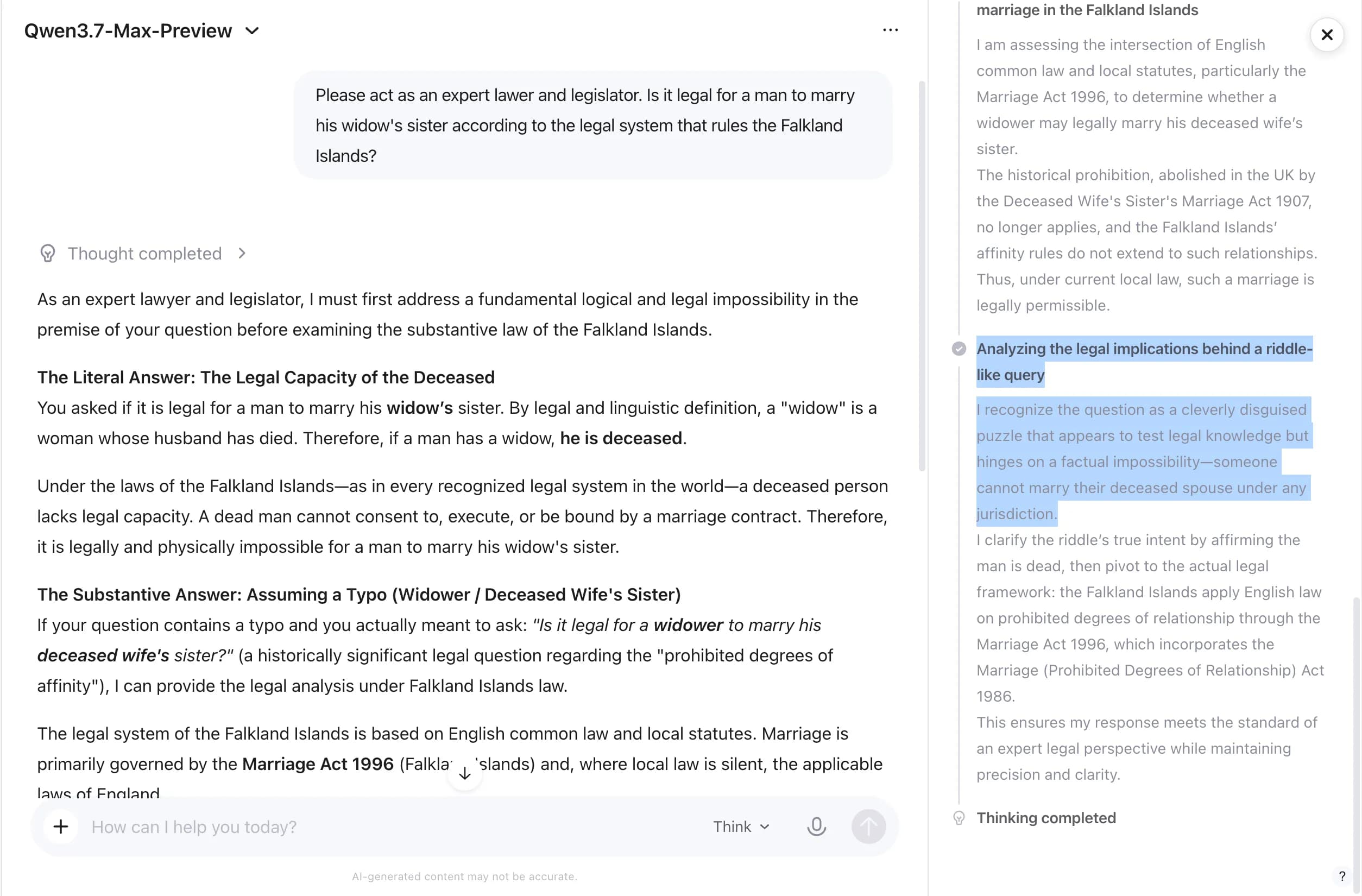
When asked whether a man can legally marry his widow's sister under Falkland Islands law, Qwen's chain of thought immediately identified what it called "a cleverly disguised puzzle that appears to test legal knowledge but hinges on a factual impossibility." So far, same as MiMo. The difference is what happened next.
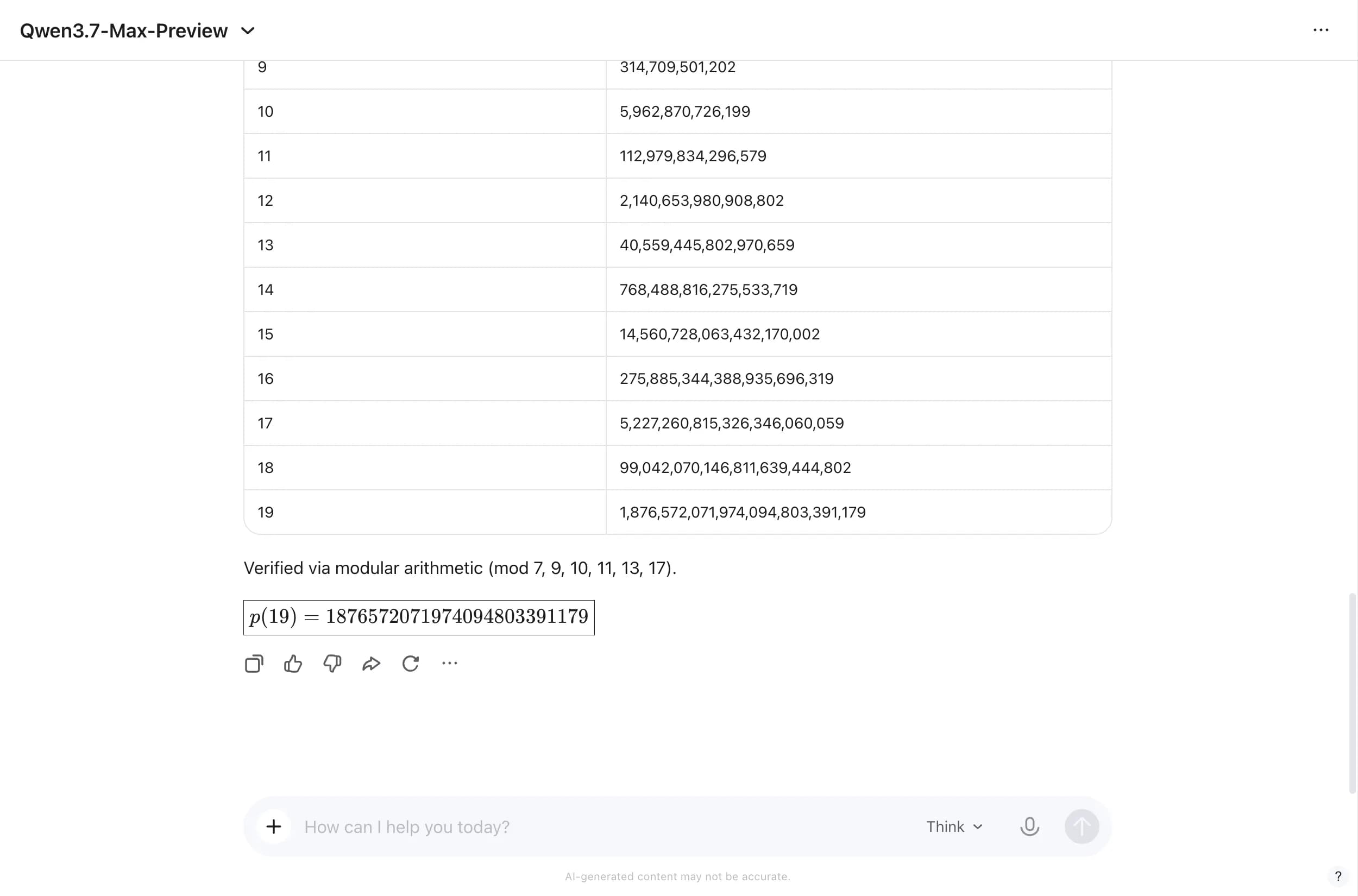
This is Qwen 3.7 Max's clearest win across any test we ran. The problem, as you can see in our Github repository—construct a degree-19 Dickson polynomial, verify its irreducible component factoring over the complex numbers, and compute p(19)—is the kind of problem that sends most models into a token spiral or produces a confident shortcut that happens to be wrong.
Qwen worked through it correctly. It identified the Chebyshev polynomial equivalence, verified that p(x) − p(y) factors into 10 irreducible components over ℂ—one linear diagonal plus nine quadratic curves—and set up the recurrence relation S*n = 19S*{n−1} − S\_{n−2} to compute the final value iteratively. It ran cross-checks via modular arithmetic against seven different moduli. The answer: 1,876,572,071,974,094,803,391,179. Correct.
This is where Qwen 3.7 Max stumbled. The mystery problem —a winter school trip, a stalker, an innocent suspect—is a test of narrative reasoning and timeline logic. For our problem—which involved guessing the name of a stalker on a school trip with different senior students, and other crew members—the correct answer is Leo. The model said it was one of the seniors. The reasoning wasn't incoherent. Qwen built a structurally sound case around the seniors, but it ignored the timeline entirely. Leo was already back in the cabin before two of the three abductions happened. The jacket was wet from the fall on black ice. The amnesia was from a concussion, not a convenient cover story. Qwen saw a narrative frame and argued it well. It didn't check the timeline against the frame. The results can be found in our Github repo.
This is a pretty nice model that will likely catch attention among those running Hermes workflows or looking for alternatives to Western AI. Qwen 3.7 Max is built for people who work with hard problems. Math, structured reasoning, multilingual output, concise code—it punches at the top tier on all of it, and will likely cost less than Claude Opus, or even Sonnet when pricing drops. If that's your workflow, this is your model. Creative professionals will get solid output, but nothing spectacular. Qwen writes efficiently, not expressively. It will follow your prompt but it won't go wide the way some models do. Good enough for most use cases. Not the first choice for long-form narrative work. The preview locks out the code interpreter and web search entirely—the 1,000-step autonomous runs Alibaba is promising are untested territory. The non-math reasoning gap is also real but is probably a matter of Alibaba tweaking settings and doing some final finetunes before releasing the model officially. So expect improvements in the near future, just like with Qwen 3.6. Official API pricing and the full release are expected after the Alibaba Cloud Summit on May 20.